p2p study
Table of Contents
p2p #
搬运
非结构化 P2P 及其搜索方法 #
上集回顾,传统的‘客户端 / 服务器’模式有一些问题,比如,单一故障点,低资源利用率,高带宽要求。我说 P2P 客服了这些问题,因为没有中央服务器了。这里,我要强调一下,并不是说只要有中央的东西就是失败,只要这个中央的东西不是那个实际掌握资源的人就可以接受。下面,简要介绍一下 P2P 技术的发展。
第一代、Napster #
这一代的 p2p 只是把资源从服务器上拿掉了。中央服务器上只有一个目录。这个目录记录着哪个用户有哪些资源。要建立这样的一个目录,要求网络中的每个人都要告诉这个服务器:他有什么资源。
- Kaka 发一个资源请求向中央服务器。
- 这个服务器然后检索目录,并告诉 Kaka,日天有他要的东西。
- Kaka 直接去找日天下东西。
这样做,解决了高带宽需求(服务器只需要转发一些消息,而不用真格的提供资源),低资源利用率的问题(网络里谁都可以发挥作用了)。但是,他仍然面临严重的‘单一故障点’风险。同时,napster 的出现严重挑战了知识产权法,并最终导致其在 2001 年被勒令关闭。
要你管👿
第二代、非结构化 P2P #
Napster 帝国的坍塌,导致了江湖上群雄并起,老的规矩也就法不责众了,其中 Gnutella 等非结构的 P2P 脱颖而出。非结构化说白了就是,用户之间瞎连,没有规定谁必须和谁有连接,基本随机。其基本搜索方法是地毯式的,如果这样的搜索能够遍及整个网络。那么,只要资源存在就一定能一网打尽。
结构化的P2P #
数学的东西我就不说了,基本的思想就是:
- 每个用户,资源都得有个名字。
- 有一种数学加密方法,对这些名字加密。且保证如果名字不同,那么得到的结果就不同。
- 如一资源和一用户加密后结果接近,就把该资源的地址放到相应的用户身上。
举个例子:
有三个人,日天,kaka,威哥。三个资源:
“一剪梅.mp3”
“八荣八耻歌歌词.txt”
“xxx.avi”
对这六个东西加密后分别得到: 100,200,3000, 3002, 233,98,‘xxx.avi’的下载地址就会被分配到‘日天’的机子上,于是当你想搜索 “xxx.avi”,你的消息就会通过某种方法被传到到日天那。
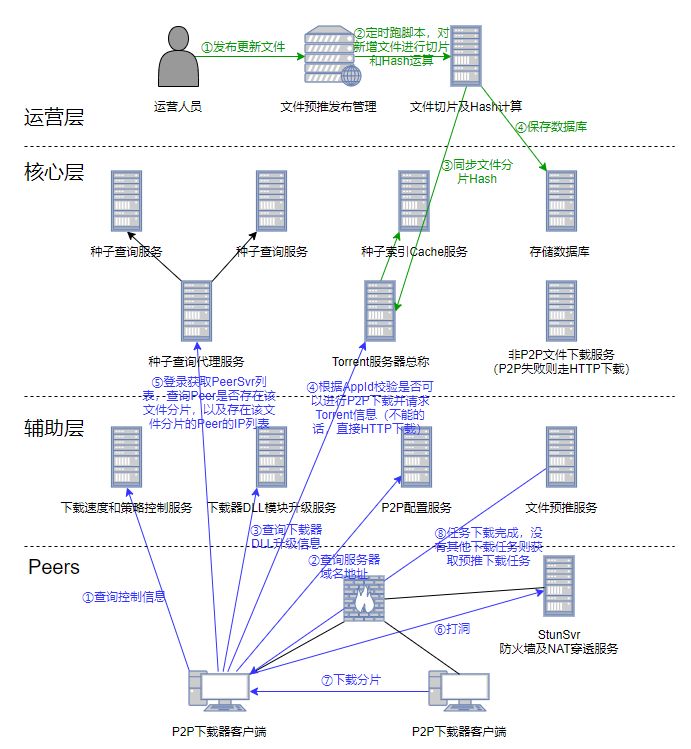
BitTorrent #
有人说 BT 是第三代的 P2P,我认为这是因为他把 P2P 的理念更加深入的实现了。
在 BitTorrent 当中,所有的资源都被切成很小的等份(碎片)。这里,你不需要知道怎么切,只需要知道有一种技术可以把一个文件切成很多小等份,还能把这些等份再重新的组装。在这个技术的支持下,bittorrent 中所有有相同请求的用户可以相互传资源的碎片。而且谁传的多,谁就将获得更多。具体技术如下:
- 首先,有同样资源请求的人怎么能相互认识呢?bittorrent 中每一个资源都对应有一个叫tracker的服务器。只要你对一个资源有意思,你就必须先联系这个资源相应的 tracker。或者你想要共享一个资源你也必须联系 tracker。这样的话,tracker 就掌握着整个网络中谁想要这个资源以及谁有这个资源。当然,为了节约,一个 tracker 可以负责多种资源。
- 那么,怎么找到 tracker 呢?大家可能听说过做种子,每个有完整资源的人都可以做种子,其实就是生成一个后缀是.torrent 的文件。每一款 bittorrent 应用软件都会自动帮你生成,所以不用担心。你只要知道这个文件中包括两部分内容:
1,tracker的地址。2,相关资源的一些属性,比如大小,名字等等。这个 torrent 文件一般都可以发布在网上,比如某某人的博客,或者论坛上。 - 于是,大家可以从网上找到 torrent 文件,并从中知道 tracker 在哪。再通过联系 tracker 得到一个名单,其中包括一部分正在下载或有完整资源的用户。这时候,你就可以与这些人建立链接,并分别从他们身上要不同的碎片。当然要相同资源的人越多,你可以建立连接的人就越多,也就更可能早日得到所有碎片。
- 还有一点很重要就是,bittorrent 有自己的鼓励机制,就是说,你做的贡献大就会被鼓励,你不做贡献就会被惩罚。具体的操作是,每个人在下载的同时也上传。上传给谁呢?谁给我给的多,我就传给谁。而且我只传个前 4 名的(视具体软件具体分析,也可能是前 8 名或其他)。
举个例子,比如 kaka 下载‘春晚’,先从某春晚发烧友论坛下载了一个叫“春晚全集.torrent”的文件。kaka 可以联系文件中的 tracker,并得知‘程胖,日天,威,候泡,鸣’有想关资源。于是 kaka 分别与这五个人建立连接。通过检测链接的流量,kaka 可知,比如从程胖那下载速度可达 200k/s, 日天 100k/s, 威 150k/s, 候泡 70k/s, 鸣 2k/s。于是 kaka 在上传的时候就不给鸣上传,而只给前 4 名传。由于鸣的上传只有 2k/s,所以不太可能有人给他传,所以时间一长他可能会意识到,可能自己给的太少了,于是把上传带宽增加到了 500k/s。kaka 突然意识到,从鸣那里可以得到很好的速度,于是停止给候泡(70k/s)传转而给鸣传。(总给那些速度最好的人上传是为了能留住他们,当然,只有你传的足够多才能留得住人家)。
当Peer与Peer下载准备开始前,会通过BT软件进行打洞(比如通过NAT设备端口有效期机制等),让彼此能够进行通信,然后进行文件分片下载。BT软件有可能同时对多个分片向多个人请求资源下载,如果下载后校验Hash失败,则会尝试其他Peer
BT方案的缺陷:
- 如果Tracker服务器异常了,则可能拿不到Peer列表(单点故障)
- 如果各个Peer失效,则可能下载超时
Kademlia技术方案 #
用于DHT(Distributed Hash Table)去中心化的P2P解决方案,解决BT方案中的单点故障问题,区块链就是应用的这种解决方案。
基本约定:
- 每个结点都有一个ID(很长),这个ID是DHT网络中某个文件某种计算方式的HASH
- 每个结点需要负责存储文件索引、文件分片等,但是每一个结点没有一个完整的知识,只有一个片段,也不知道所有的文件片段保存在哪里
- 每个文件计算出来HASH,那么结点ID与此HASH相同或者相似,这个结点就需要知道该文件存储在哪里
王尼玛 用户结果计算后得出“王“这个结果,资源《老王的爱情故事》在计算后得出王这个结果,故王尼玛用户需要储存《老王的爱情故事》的具体存放位置
Session建立原理:
- node new上线,需要下载文件1
- 首先,node new需要获取文件1的种子文件,这个种子文件中,会包含一部分结点的地址以及文件1的Hash
- node new根据文件1Hash,在种子文件中这些已知的结点中问询,查找与Hash相同或相似的结点信息
- 各个结点,收到node new的请求,会首先看自身是否满足要求,如果不满足要求,就会进一步广播此请求(有种类似社交网络中找人)
- 一旦找到了结点(我们这里是node C,包含了文件1的索引),就会回复告诉node new,需要分别去B、D、F查询
- node new先与B进行Peer连接,开始下载,自己本地也有文件1了,就会告诉node C和ID相似的结点,自己也存在文件1了,可以加入那个文件的拥有者列表
- node C和其他文件1索引拥有者会将node new也加入到文件1的索引列表
长大后,我就成了他